The complicated relationship of domain and persistence
It was only yesterday when I blogged about .NET Solution structure of an enterprise application. I got some feedback from my colleagues about that post. One of the confusions was, why would I make the persistence project depend on the domain project? In this blog post I try to give a complete answer to that design choice.
The argument against persistence depending on domain
The message I received was that the persistence project should not depend on the domain project. Argument was that this violates the layered architecture and leaks the domain outside of it’s project. One question was, how is persistence different from the other layers which operates through the request and response DTOs? Why not follow the same reasoning when it comes to Persistence? There was also a concern that persistence layer need to be changed every time the model changes. Decoupling layers would solve this issue, I heard.
That’s a bunch of really good questions! Let me try to navigate through them and illustrate on the code level why making Persistence project to depend on Domain project is actually a good idea.
The domain leakage
One of the main concerns seemed to be that no other project should know about the inner-structure of the domain excluding the domain project itself. Fair enough, even the business layer doesn’t know what the aggregates consist of, instead it just uses the interfaces of the aggregate roots to manipulate the state of the system. The keyword here is uses. I’m totally onboard when it comes to restricting usage and modification of the domain aggregates. One of the aggregate’s responsibility is, after all, to make sure that it is always in a consistent state. It would be hard to obey this rule, if business code could change the internal state of an aggregate as it wishes.
However, the relationship between persistence and domain is completely different. Persistence doesn’t use the domain model. It doesn’t change the state of it. Instead persistence layer’s only responsibility is to persist the current state of an aggregate as it is. And the most convenient and clear way to do that is to allow it access the state of the aggregate directly.
Also consider this, the business layer using the domain depends on it on a conceptual level and this dependency exists at runtime. On the other hand, the dependency between persistence layer and domain is technical and exists only at the compile time. This is exactly why inverting the dependency is such a powerful concept. We can depend on code level to the opposite direction of logical dependency.
Why do we decouple?
We decouple domain from persistence and other technical code, because we want to protect it from change. The domain is the unique and valuable part of our application. Persistence is something that all enterprise apps do. That’s why there are so many tools that can help us to implement it. Persistence is a detail, domain is what matters. Domain deserves the protection, persistence, not so much. For more, it is conceptually impossible to any persistence implementation not to depend on an aggregate state. The only question is, do we depend on it directly or indirectly?
What would decoupling mean?
To find an answer to the question “Should we depend on aggregate state directly or should we introduce another level of abstraction between these layers”, let’s consider what it would mean to make persistence project not depend on the domain project.
The first obvious thing we notice is that we need some objects to represent the state of the aggregates. It’s also clear that persistence should be able to depend on those objects. Let’s call these objects state DTOs. So where do we put them? Surely they can’t be in the domain project since we are trying to avoid referencing that from the persistence. Therefore we need to introduce a new project for these state DTOs and reference it from the persistence instead. The next question is, where do we map back and forth between these state DTOs and domain aggregates? Given the leakage premise, the only acceptable answer is in the domain project. Any other option would leak the implementation of the aggregates outside from domain and that is exactly what we are trying not to do here. This decision leads us to reference our new state DTOs project from domain as well.
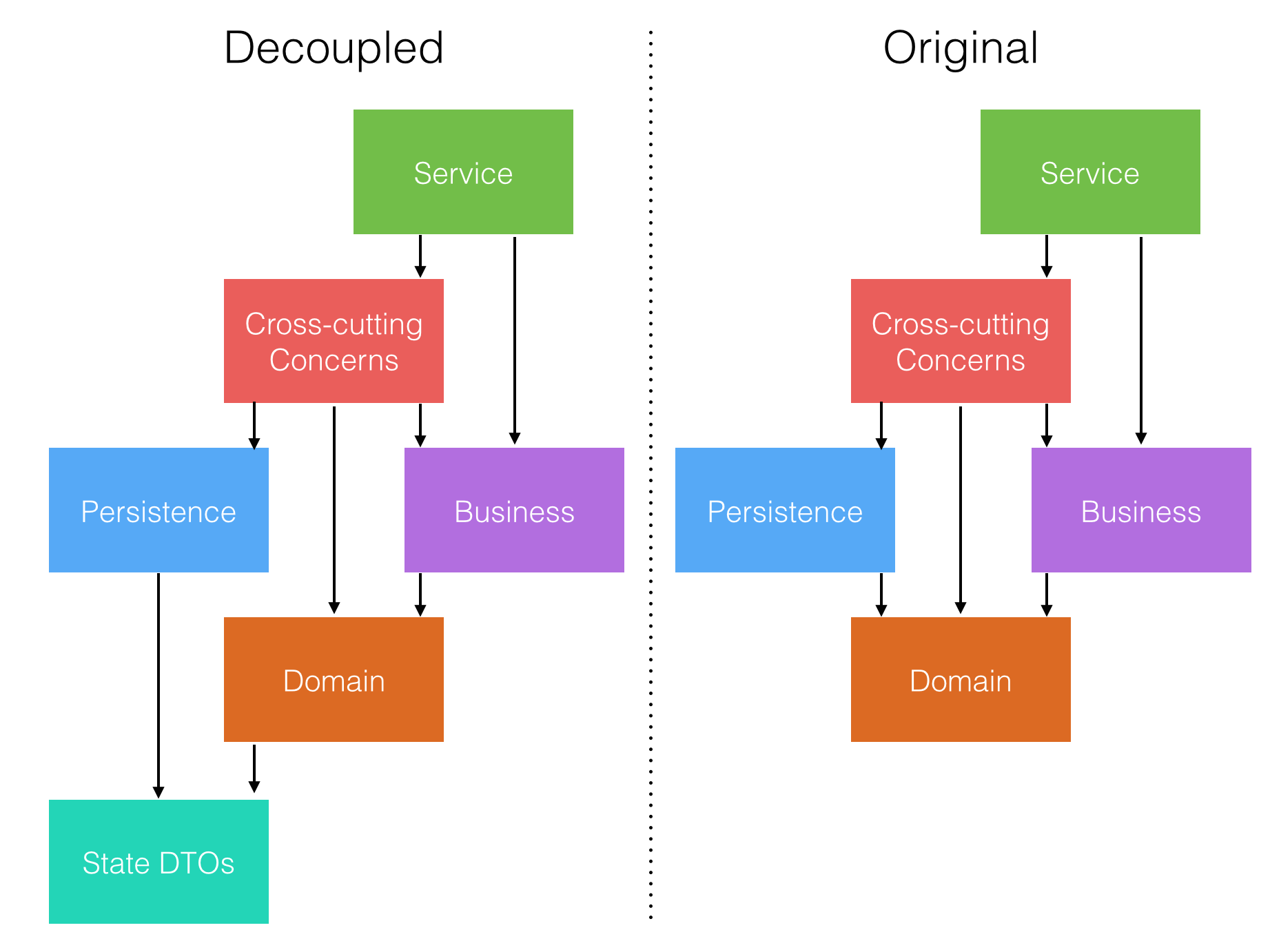
Next we need to change our thinking a bit. Now the persistence layer does not persist
domain objects anymore, but the state DTOs. This means that persistence layer shouldn’t
implement the repository interfaces in the domain. After all, those depend on domain
concepts, because they contain methods like Save(IInvoice invoice) and
IInvoice GetByNumber(string number).
So what do the persistence layer implement then? We need to introduce a new interface
for these “state DTO repositories”. I find it confusing to call these repositories as
well, so I’ll call them persistence adapters to make clear distinction between domain
repositories and these DTO driven persisters. The next question is, where to put this
interface? Our new project seems appropriate place since it’s the shared part between
persistence and domain. In practice this state persistence adapter interface is a
copy of the repository interface with the exception of using DTOs in the interface
instead of domain concepts. Instead of having Save(IInvoice invoice) it has
Save(InvoiceStateDto dto).
The last missing part is the repository implementation. With this model that goes into domain project. Basically this repository implementation works as a gateway between the domain and persistence adapter.
I implemented this decoupled version of the architecture and put it into Github for anyone to take a closer look. For comparison, you can find the original version from here. Now we have implemented a new version of the architecture which doesn’t introduce any direct dependency between the persistence and domain.
The benefits of decoupling
Let’s take a step back and see what we have achieved with this exercise. Persistence project does not depend on the domain project. Checked!
Now we can modify domain aggregate structure without modifying the persistence layer. True, but we do need to update our mapper that we didn’t have before. So instead of modifying the mapping in the persistence layer we modify mapping in the domain layer. For more, if you check the repository I had in my previous blog post, you’ll notice that there wasn’t actually any mapping in it. Indeed, using e.g. MongoDb as a persistence technology you can modify your domain aggregate freely without modifying anything else at all. This is of course true only as long as the system is not in the production. After that step, mapping needs to be updated in the mongo repository as well. Even still, the development phase will be so much faster and more enjoyable when you don’t need to keep things in sync all the time. If you use traditional SQL database and ORM mapper, then the mapping needs to be changed in persistence the same way it needs to be changed in new mapper in domain layer. So here, the benefit seems to be that we isolate the modification into one project instead of two. This can be useful, if you dedicate separate teams to work on different layers of the application.
Now we can modify persistence without affecting the domain. Well, this was true already when persistence depended on the domain. So, this isn’t really a benefit added by the updated architecture, but it is still important!
Any other benefits I couldn’t find from this architecture compared to the original one introduced in the previous blog post. I truly wish someone tells me if there is something more to gain by this decoupling. I’m really eager to understand the whole picture here.
The price of decoupling
When we went through the required modifications to the architecture in the beginning of post, it became quickly evident that implementing this decoupling doesn’t come for free. We needed to sacrifice many things to achieve it. Let’s consider what is the price of this change in more detail.
We added a new project to the solution and introduced a new level of abstraction by introducing new repository implementations on top of the persistence adapter implementations which mostly stayed the same. The new repository implementation maps the entity into state DTO and delegates persisting to the persistence adapter in the persistence layer.
We also introduced new mapping code. Not only that, the DTO mapper was implemented into domain project. It’s clearly not a place for such a technical requirement as DTO mapping. Domain should be all about the modeling. There is no way around this issue if we decide that aggregate structure shouldn’t be visible to other projects. Mapping is clearly a cross-cutting concern, its not domain specific, its in all enterprise applications and there are nice libraries to automate the effort. It would be tempting to add a reference from domain project to such a library, but it would make things only worse. Our domain would depend on technical library that has nothing to do with domain.
Consider an application with multiple complex aggregates. This is a considerable amount of new code to be maintained. Mapping, DTOs, extra interfaces and repositories. Not to mention how it increases the complexity of the overall system architecture. The worst part is that this is boilerplate code. It’s something you always need to do just to keep things running. Everytime you refactor, add or remove properties, there are these extra steps you need to take.
Finally, introducing a new abstraction layer between persistence and domain prevents us utilizing some of the features available in the most advanaced ORM-tools. Lazy loading is one of those features. For example, NHibernate can be configured so that it lazy loads parts of an aggregate only when needed. Of course, this lazy loading is not visible at all in the domain and business layers. When working with SQL databases, it can be a huge benefit that not all parts of the aggregate are always loaded eagerly. There might be an expensive part to load that is rarely needed in business operations, yet it still clearly belongs to the aggregate. In these cases we want to utilize lazy loading. However, if you have a DTO layer in the middle, this is not possible anymore. DTO layer forces aggregates to be loaded eagerly everytime needed or not.
Conclusions
I’m not saying it’s a bad idea to decouple persistence and domain from each other on a conceptual level. What I’m saying is, that the price we need to pay as added complexity, maintenance and polluting domain with technical concerns does not justify the benefits it provides. Not all of these prices are obvious until you start to implement decoupling on code level. As always with design decisions, it comes down to comparing the benefits against the price and here the conclusion seems clear to me.
There is this special case of having different teams working on these layers. This is rather old-school way of scaling the development and luckily not too common in a modern day development. Nowadays, we scale rather vertically than horizontally. However, if you are stuck in an organization that imposes this type of scaling, then this complete decoupling might be feasible solution to consider. Still I would consider it really really long, before applying. It won’t completely remove dependency between the teams anyway. It’s probably still easier to work with the dependency between the projects than with all the extra whistles and blows.