.NET Solution Structure of an Enterprise Application
After reading multiple DDD-books (all two of them) and studying architectures like Onion, Clean and Hexagonal, I have tried to come up with a good .NET solution structure that enables developing a well architected enterprise application with domain-driven development while following the SOLID principles. In this blog post I will build such a solution step-by-step while explaining the reasons behind each design decision. You can find the complete solution from the GitHub with one commit for each step of the post.
I hope this blog post is useful for other developers struggling to map the high-level concepts of SOLID, DDD and architecture into an actual code.
Domain
We start by creating a new solution with Visual Studio. Let’s choose a library project and give it a name EnterpriseApplication. Visual studio creates a new solution with one library project. Let’s rename this project to Domain. This project will be the core of our application containing all the entities. I recommend creating a folder for each aggregate root right under the domain project. This convention makes aggregate boundaries visible on the solution level and you can immediately see what are the key concepts of the domain. Notice that we organize the code around domain concepts instead of technical concepts like factories, mappers, validators etc. This does not only help communicate the domain, but also makes it easier to find the piece of code that you are looking for.
For the sake of demonstration let’s add Invoice aggregate root. First I add IInvoice
interface that represents the concept in our domain. Next we need to create a factory
to be able to create our invoices, so I add InvoiceFactory class and also an actual
implementation class for the IInvoice interface. Factories and the entities that they
create are highly cohesive and belong next to each other in the solution, that’s why I
put them side-by-side into the domain project.
namespace Domain.Invoice
{
public interface IInvoice
{
void ChangeDuedate(DateTime newDuedate);
}
}namespace Domain.Invoice
{
public class Invoice : IInvoice
{
public Guid Id { get; set; }
public string Number { get; set; }
public DateTime Duedate { get; set; }
public void ChangeDuedate(DateTime newDuedate)
{
// There is more complex logic, but thats not the
// point of this blog post and therefore skipped.
Duedate = newDuedate;
}
}
}namespace Domain.Invoice
{
public class InvoiceFactory
{
public virtual IInvoice Create(string number, DateTime duedate)
{
return new Invoice
{
Id = Guid.NewGuid(),
Number = number,
Duedate = duedate
};
}
}
}There is still one concept to add to our domain project and that is repository for our
aggregate root. Not the implementation, but the interface! So let’s add IInvoiceRepository
to the Invoice folder. We add the interface there, because whoever depends on the domain
and it’s aggregates also wants to create (factory) and persist or reconstitute (repository)
those aggregates. Therefore it’s a natural place for the interface.
namespace Domain.Invoice
{
public interface IInvoiceRepository
{
IInvoice GetById(Guid id);
IInvoice GetByNumber(string invoiceNumber);
void Save(IInvoice invoice);
}
}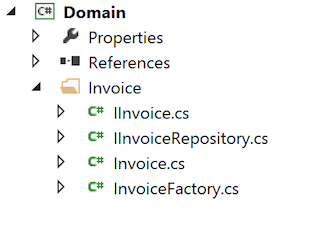
To conclude, our Domain project consists of folders that represent aggregates of the domain. Each folder contains factory, entity and repository interface of the specific aggregate. This is an aggregate in its simplest form. Usually there are also multiple value objects and entities related to the aggregate.
Business
Next step is to create a new project for Business layer. We add a new library project to the solution and call it Business. Where as the domain layer contains the domain logic in the form of aggregates, the business layer is a home of the business logic. This layer implements all the use cases of the application. One use case is usually one business operation that operates on one or more aggregates of the domain. Therefore business layer naturally depends on the domain layer. So let’s add a project reference from Business to Domain.
If you think about any business application, they always consist of two kind of operations: commands and queries. Commands modify the state of the system, but never return any data. On the contrary, queries allow reading the system state without modifying it. This idea is also known as Command Query Responsibility Segregation (CQRS). However, I won’t introduce separate read model in this example. Instead I use one model to implement both, queries and commands, meanwhile still making a clear separation on those operations on the architectural level. There is no reason that would prevent introducing the new read model for queries as the need arises, but I would always start with a single model and use it as long as it’s feasible.
To make this idea visible in our solution architecture, let’s create two new folders under our Business project and name them Commands and Queries. Now under the Commands folder I create a folder for each business operation / use-case. This way by looking the business project you can instantly see all the business operations that are supported by the application. Folders and business operations should be part of the Ubiquitous Language just like the domain aggregates are.

For this example, let’s add a simplified business operation to change the invoice due date. We
create a new folder for it and call it ChangeInvoiceDuedate and right under it we create new
class called ChangeInvoiceDuedateCommand. I use a naming convention of suffixing all the entry
points of the business commands with Command. This becomes handy later when we configure our
DI container.
namespace Business.Commands.ChangeInvoiceDuedate
{
public class ChangeInvoiceDuedateCommand
{
IInvoiceRepository invoiceRepository;
InvoiceDueDateChangeValidator validator;
public ChangeInvoiceDuedateCommand(IInvoiceRepository invoiceRepository)
{
this.invoiceRepository = invoiceRepository;
this.validator = new InvoiceDueDateChangeValidator();
}
public void Execute(ChangeInvoiceDuedateRequest request)
{
if(validator.IsDuedateValid(request.NewDuedate))
{
IInvoice invoice = invoiceRepository.GetByNumber(request.Number);
invoice.ChangeDuedate(request.NewDuedate);
invoiceRepository.Save(invoice);
}
else
{
throw new InvalidDueDateException();
}
}
}
}To implement ChangeInvoiceDuedateCommand I use constructor injection pattern to inject
dependencies of the command. As a dependency we need IInvoiceRepository to be able to fetch
the invoice which due date should be changed. Notice that we can access this repository
interface since it was located to domain project that business depends on. For the sake of
this example, I also added a class InvoiceDueDateChangeValidator to illustrate that business
layer contains not only entity calls but also business rules that are not part of the aggregates.
Rules when due date of an invoice can be changed are part of the business operation. How the due
date is changed and how it modifies the aggregate state is part of the domain logic and therefore
in the invoice aggregate. Also notice that validator is not injected, but created by the command.
It’s highly cohesive with the command and there is no need to inject it from the outside.
namespace Business.Commands.ChangeInvoiceDuedate
{
public class InvoiceDueDateChangeValidator
{
public bool IsDuedateValid(DateTime duedate)
{
// Dummy validation for illustration purposes
return duedate > DateTime.Today;
}
}
}One more noteworthy design decision here is the request object that comes as a parameter to the command. Whenever command or query is called, request object is given as a parameter (and the only parameter). The request encapsulates all the data that is needed for that specific query or command. Requests are simple data transfer objects (DTO) and are named with Request suffix.
namespace Business.Commands.ChangeInvoiceDuedate
{
public class ChangeInvoiceDuedateRequest
{
public string Number { get; set; }
public DateTime NewDuedate { get; set; }
}
}I won’t go into details of implementing a query in this example. I will mention however that all the queries return Response objects that are similar to requests but move to another direction. So basically in query implementation you fetch what ever aggregates are needed to produce the response and then map. To conclude, all the data that crosses the business layer boundary is within request and response DTOs.
Persistence
Now that we have a domain and business layer in place, let’s create a persistence layer!
I add a third project to our solution and name it Persistence. As you can imagine, the
responsibility of this layer is to implement data access for our domain. You might recall that
our repository interfaces were put into domain project. Persistence layer implements those
interfaces so let’s add a new project reference from persistence to domain. Now that we have
referenced the domain, let’s add a new class called InvoiceRepository and make it implement
the IInvoiceRepository introduced earlier in Step 1. In this example I will use MongoDB
to actually implement the repository. If you choose to use SQL database I recommend using
Entity Framework or NHibernate instead. Below is a naive implementation
of the repository that is sufficient for this example.
namespace Persistence
{
public class InvoiceRepository : MongoRepository, IInvoiceRepository
{
public InvoiceRepository(MongoClient mongo) : base(mongo) { }
public IInvoice GetById(Guid id)
{
return Invoices.AsQueryable<Invoice>()
.Single(c => c.Id == id);
}
public IInvoice GetByNumber(string invoiceNumber)
{
return Invoices.AsQueryable<Invoice>()
.Single(c => c.Number == invoiceNumber);
}
public void Save(IInvoice invoice)
{
Invoices.Save(invoice);
}
MongoCollection Invoices
{
get { return Database.GetCollection<IInvoice>("invoices"); }
}
}
}That’s all when it comes to persistence layer. It’s a rather thin layer containing repository implementations. Since the persistence project depends on the domain project it can easily instantiate entities when reconstituting objects from the database. In case of MongoDb, there isn’t even need to do manual mapping since mongo does everything for you automatically. One thing to point out is that the domain aggregates do not use constructor injection pattern. Instead they instantiate the dependencies themselves. Again, classes within the aggregates are highly cohesive with each other and therefore can depend on each other as needed.
Cross-cutting Concerns
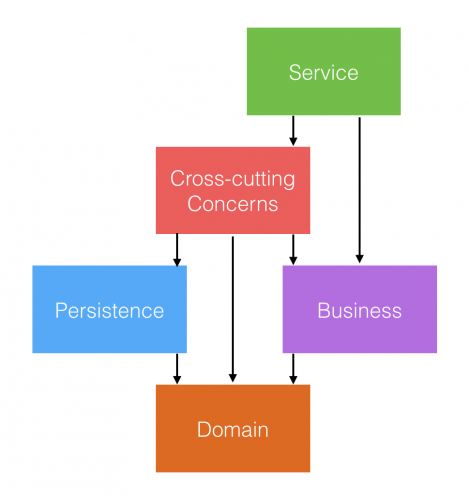
Now we have three projects in our solution: Domain, Business and Persistence. All with very specific responsibilities. Both Business and Persistence depend on Domain, but there are no other dependencies between the projects. Next it’s time to stitch everything together. Let’s create a fourth project to our solution and call it CrossCuttingConcerns. As the name of the project implies this project contains all the features that are cross-cutting to all layers of the application. These include for example logging and auditing, but more importantly dependency injection.
Let’s add a new folder for each cross-cutting concern under the project. I create folders named DependencyInjection and Logging for this example app. In real apps there could be also Security, Auditing, Monitoring, RequestValidation etc.

Next, let’s add project references from the CrossCuttingConcerns project to all the three projects we created before: Domain, Business and Persistence. Due to the nature of cross-cutting concerns, it’s ok that this project depends on all the others. More importantly, domain project still depends on nothing and business depends only on domain. Those are the two projects that are the core of our system, the part that make our system unique and valuable. In contrast, Persistence and CrossCuttingConcerns are the projects that implement responsibilities that are common to all enterprise systems including database access, logging and DI, just to mention few. If you think about it, these two projects are the places where we want to utilize already existing technologies like IOC containers, ORMs, Mongo drivers, Validation frameworks, Logging frameworks and the list just goes on.
This is great, because our architecture makes it so that all these external dependencies are in the projects that do not contain any business or domain logic. Decoupling the external dependencies is important, because we don’t want to depend on those details. Instead we want those details to depend on our core! Dependency injection (see DIP) allows us to inject these cross-cutting concerns into appropriate places of the application stack without making the stack depend on those concerns or their implementations. This can be done with decorator pattern or by using intercepting supported by some DI containers.
In this example app I use Castle Windsor as IOC. I won’t go into details how Castle works, but I have chosen it because it implements two crucial features: Intercepting and Convention based registering.
Let’s start by implementing simple error logging. Castle makes it easy, because it provides
integration for log4net out-of-the-box. I’ll create an ExceptionLogger class
into the Logging folder and make it implement IInterceptor which is castle’s interface
for intercepting method calls. Implementing the logger itself is easy. Below is the full
implementation of the error logger that can be used throughout the system.
namespace CrossCuttingConcerns.Logging
{
public class ExceptionLogger : IInterceptor
{
ILogger log;
public ExceptionLogger(ILogger log)
{
this.log = log;
}
public void Intercept(IInvocation invocation)
{
try
{
invocation.Proceed();
}
catch (Exception e)
{
var message = string.Format("Method '{0}' of class '{1}' failed.",
invocation.Method.Name,
invocation.TargetType.Name);
log.Error(message, e);
throw;
}
}
}
}Now that we have all the pieces in place, let’s implement Composition root of the
application. I will do this by creating a new class CompositionRoot under DependencyInjection
folder. Castle Windsor supports splitting the composition root into smaller components called
Installers. I prefer creating an installer per project/layer to keep my codebase well organized.
Below you can see the implementation of the CompositionRoot and all the installers.
namespace CrossCuttingConcerns.DependencyInjection
{
public class CompositionRoot
{
public virtual void ComposeApplication(IWindsorContainer container)
{
container.AddFacility<LoggingFacility>(f => f.UseLog4Net());
container.Install(
new CrossCuttingConcerns(),
new Persistence(),
new Domain(),
new Business()
);
}
}
}public class Domain : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
container.Register(Classes.FromAssemblyContaining<InvoiceFactory>()
.Where(type => type.Name.EndsWith("Factory"))
.WithServiceSelf()
.LifestyleSingleton());
}
}public class Business : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
container.Register(Classes.FromAssemblyContaining<ChangeInvoiceDuedateCommand>()
.Where(type => type.Name.EndsWith("Query"))
.WithServiceSelf()
.Configure(c =>
c.LifestyleSingleton().Interceptors<ExceptionLogger>()));
container.Register(Classes.FromAssemblyContaining<ChangeInvoiceDuedateCommand>()
.Where(type => type.Name.EndsWith("Command"))
.WithServiceSelf()
.Configure(c =>
c.LifestyleSingleton().Interceptors<ExceptionLogger>()));
}
}public class Persistence : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
RegiterMongoDb(container);
RegisterRepositories(container);
}
protected virtual void RegiterMongoDb(IWindsorContainer container)
{
var mongoClient = new MongoClient("mongodb://localhost");
container.Register(Component.For<MongoClient>().Instance(mongoClient));
}
void RegisterRepositories(IWindsorContainer container)
{
container.Register(Classes.FromAssemblyContaining<MongoRepository>()
.BasedOn<MongoRepository>()
.WithServiceFirstInterface()
.LifestyleSingleton());
}
}public class CrossCuttingConcerns : IWindsorInstaller
{
public void Install(IWindsorContainer container, IConfigurationStore store)
{
container.Register(Component.For<ExceptionLogger>());
}
}As you can see, I register most the classes by convention for each layer. I also bind the logging interceptor to all Commands and Queries. This guarantees that any exception thrown from domain, business or persistence will always get logged. Thanks to convention based configuration, there is no need to modify composition root when we add new aggregates, repositories or business operations to our application. It all just works as long as the classes are named by convention.
One important aspect of the dependency injection here is that we inject dependencies only at the boundaries of the layers to decouple them from each other. However, within the domain and business layers I tend to create dependencies locally, since the classes are highly cohesive with each other within use-cases and aggregates.
Services layer
So far we have four projects in our solution: Domain, Business, Persistence and CrossCuttingConcerns. These four projects together fully implement the system, but there is still one minor problem to solve. We can’t use the system at all! We need a delivery mechanism over business layer to be able to call commands and queries of the system. In this example, I will create a WCF service over the business layer to enable access to our domain. This layer could be REST, MVC, WPF or even a command line application, but for this example it’s WCF. There is also no reason why this layer should be limited to only one. We could have WCF and WPF living side-by-side in our application.
Let’s create a new empty ASP.NET Web project to our solution and call it Services.
This project’s responsibility is just to enable remote access to domain. It does not
contain any logic and it’s a really thin layer over the others. No other project depend
on this layer. Services layer itself depends on CrossCuttingConcerns and
Business. So let’s add project references for those two dependencies! Next we
implement a trivial InvoiceService that has a method for changing the due date of
an invoice. This class binds remote interface to our business layer. We inject our
ChangeInvoiceDuedateCommand as a constructor parameter into our service so that it
can delegate the call to the business layer.
public class InvoiceService : IInvoiceService
{
ChangeInvoiceDuedateCommand changeInvoiceDuedate;
public InvoiceService(ChangeInvoiceDuedateCommand changeInvoiceDuedate)
{
this.changeInvoiceDuedate = changeInvoiceDuedate;
}
public void ChangeInvoiceDuedate(string invoiceNumber, DateTime newDuedate)
{
var request = new ChangeInvoiceDuedateRequest
{
Number = invoiceNumber,
NewDuedate = newDuedate
};
changeInvoiceDuedate.Execute(request);
}
}That’s almost all that there is to services layer (in this example application). But there
is still one trick we need to do. We need to somehow register our service to IOC so that
the WCF framework can create the services for us with dependencies in place. To do this
we need to tell WCF framework to use our IOC container as a dependency resolver. We also
need to register services on the service layer to the container before rest of the
application is configured within the composition root. To do this let’s add Global.asax
file to our Services project. This class contains a method Application_Start() that
is executed when the application is started by IIS. Below is the code illustrating how to
bootstrap dependency injection with WCF.
public class Global : System.Web.HttpApplication
{
WindsorContainer container;
protected void Application_Start(object sender, EventArgs e)
{
container = new WindsorContainer();
container.AddFacility<WcfFacility>();
container.Register(Classes.FromThisAssembly()
.Where(type => type.Name.EndsWith("Service"))
.WithServiceDefaultInterfaces()
.Configure(component =>
component.Named(component.Implementation.FullName)));
new CompositionRoot().ComposeApplication(container);
}
protected void Application_End(object sender, EventArgs e)
{
if (container != null)
container.Dispose();
}
}As you notice, we actually create the WindsorContainer already in the service layer,
configure controllers to it by convention and then pass the container to our composition
root, which in turn, configures the rest of the application. We do this, because we can’t
configure controllers in the composition root that is located inside CrossCuttingConcerns
project. Remember that CrossCuttingConcerns does not depend on Services project.
We could move the whole dependency injection configuration to service layer, but that would
couple DI tightly to delivery mechanism. What if we want to add WebAPI next to WCF? No, we
don’t want to couple those two concerns too tightly. By locating DI to CrossCuttingConcerns,
we have it separated while allowing any top layer to utilize it to configure the application.
Conclusions
Let’s take a step back and see what we have achieved here. We have implemented a basic structure of an enterprise system in .NET. It consists of five projects, Domain, Business, Persistence, CrossCuttingConcerns and Services. All these have clear responsibilities and interfaces. The architecture is not specific to any domain. Domain specific code is always located in the Domain and Business projects that are completely independent from the rest of the system. This total decoupling between domain specific logic and technical requirements is one of the biggest advantages of this architecture.

This is an enterprise application architecture in its simplest form. It’s not rare that we have sub domains side by side with core domain or Application layer on top of the business layer. This blog post was already way too long without those, so I just left them out of this exercise.
Pros
- Architecture follows SOLID principles.
- Solution structure screams the domain with a folder structure that is built around the domain concepts and processes. Notice that there are no folders named Validators, Exceptions, Factories or so.
- Clear separation of concerns on the project level. All the code could be in one big project, but I find it helpful to organize code on layer level. Also managing dependencies between these projects enforces decoupling the high level concepts from each other.
- Cross-cutting concerns are isolated and put into a clearly named folders. You can immediately see what are the cross-cutting features of the system on the solution level. More importantly, logging, security, audit etc. are not polluting the domain and business code.
- Persistence implementation is separated from the domain allowing domain model to differ from the persistence model. This also enables adding technical features to persistence in OCP manner. For example, adding caching is as easy as creating a caching decorator for repository implementation and configuring it with composition root.
- Service layer stays extremely thin and rest of the application doesn’t need to know about it’s existence.
- Using Request and Response DTOs on the business layer boundary decouples the upper layers from the domain concepts. Business layer can provide API suitable for the upper layers. These DTOs also define the data interface of the application: what data is needed for each operation.
- All technical frameworks are isolated from the actual business code which makes it easy to switch any as needed. Wanna use Unity as IOC? Just rewrite the stuff within DependencyInjection folder. Wanna use EntityFramework instead of MondoDb, just rewrite a repository in Persistence. Wanna use WebAPI instead of WCF? Just implement another Service layer next to WCF. None of these changes, require any changes to the core of the application.
- Adding a new business operation to the system is easy. Add a new Command to the business layer and possibly new functionality to one or more aggregates. This follows the OCP principle which states that the system should be open for extension, but close for modifications. We don’t need to touch any existing business operations while adding a new one. We also shouldn’t need to modify aggregates since the domain concepts stay the same across the business operations. We might need to add new domain functionality though.
- I feel I have to mention testing here. It’s a whole new topic for another blog post that I wrote earlier, but let’s just mention that testing an application following this architecture is not only easy, but fun!
Cons
- Dependency injection cannot be kept completely in Cross-cutting concerns, because of the nature of it. We need to be able to register the very “top level” classes of the application to the container and those classes are always on the layer above everything else.
Your turn! Leave a comment and help me improve this solution structure and architecture. Tell me what are the weak points of it. Is there a way to make it less complex without compromising benefits it provides?
After feedback I wrote a follow-up blog post. Read it from here.